Data architecture
In this section, we are describing the way our platform transforms your data once it is ingested. The schema below summarizes the different steps of this transformation.
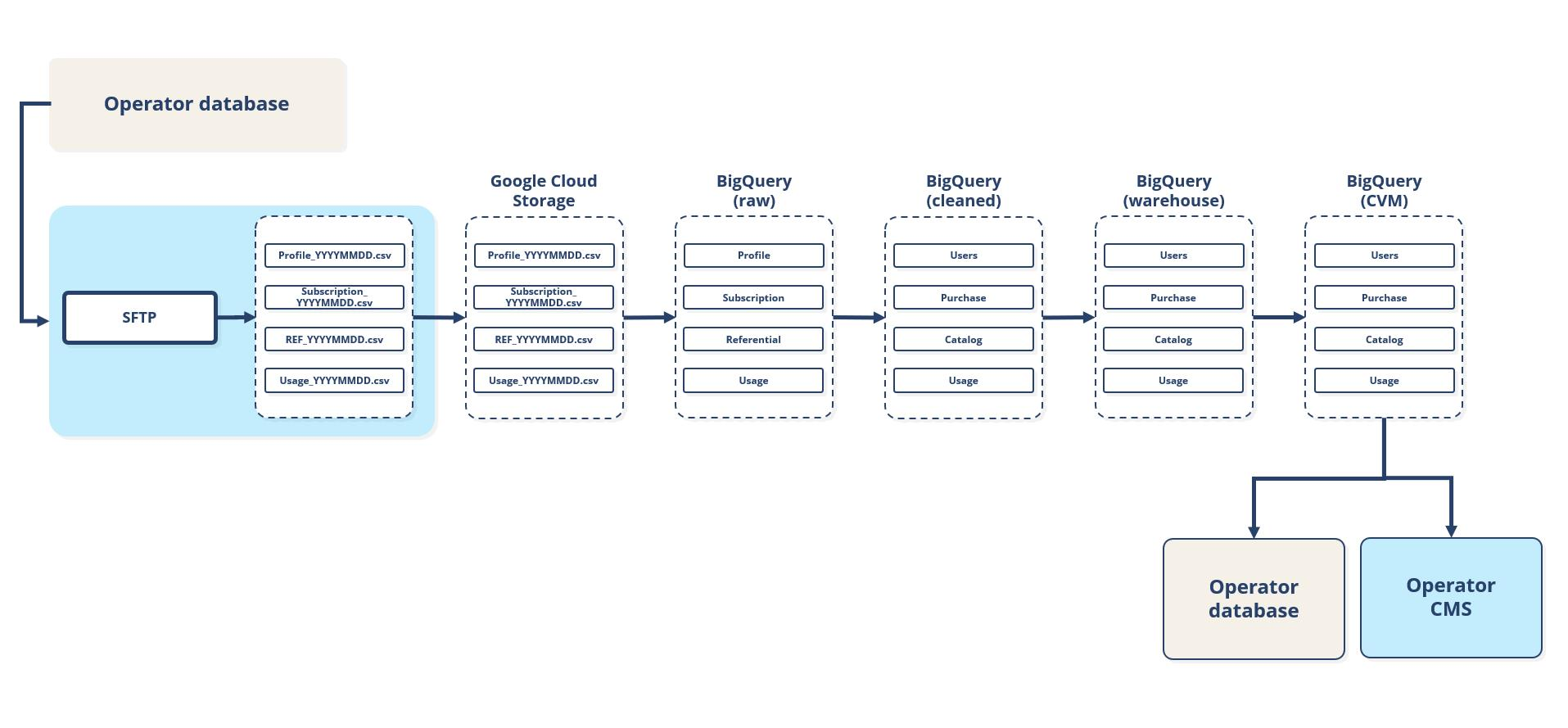
1. From data sources to Google Cloud Storage
You import your different files described in the Data Requirements section to the SFTP server. Here we are presenting the most common use case, including one source: your database. You can of course have more sources providing files into the SFTP.
2. BigQuery Raw
This step allows us to split the data into 1 partition per day, using a YAML configuration file, specific to your needs. We also control the file header at this step.
3. BigQuery cleaned
This part of the transformation process allows us to operate the standard modifications to your data, common to all our clients:
- Deduplication: We deduplicate users following the rules and the unique key for each data source defined during the setup. Please read our functional guide on this topic if you want to know more.
- Casting: We apply a type to fields when necessary. For example, we can transform a date field in a string format into a date-typed field.
- Filtering: We filter out the records that do not match our requirements described in the Data Requirements section. For example, we set aside all users without a user_id.
- Naming: We rename the fields based on the rules defined during the setup, to enable calculations.
4. BigQuery Warehouse
At last, in this step, we apply the specific transformations to your data set, using a DBT framework (data build tool), to build our standard data model for all downstream computation.
- Join: We regroup files in cases where we have several files for the same entity from different sources. For example, if we have users coming from your e-commerce and your main database, we merge them at this step.
- Filtering:“We apply a post-join condition to filter out records that don’t match our data model requirements.
- Identity resolution (optional add-on): The process reconciling the same users from different sources is applied here (ajouter le lien vers l'article Stonly)
- Exposing final data tables: At last, we are able to give you access to the cleaned and unified database.
5. BigQuery CVM
We use another specific dataset to give access to all the data in the CDP. The main use case here is to use this data in your Business Intelligence platform.
Updated 27 days ago